k/OS. A Multitasking OS for K16 CPU
Developer notes: Building k/OS from scratch on the K16 CPU — the design decisions, the bugs, the discipline, and the ISA changes that fell out of writing real OS code.

K16 CPU Overview:
A 16-bit discrete logic CPU with 24-bit addressing, built from approximately 81 TTL chips, 6 ALU/control ROMs, and 13 chips of external glue/memory.
The K16 is a homebrew CPU designed around ROM-based lookup tables for both ALU operations and instruction decoding. Rather than using traditional hardwired logic, the K16 leverages high-density flash ROMs to implement complex functionality while keeping the chip count reasonable.
k/OS is the K16 multitasking operating system, verified bit-exact across emulator and gate-level simulator.
Part 1 — how one register holds it all together
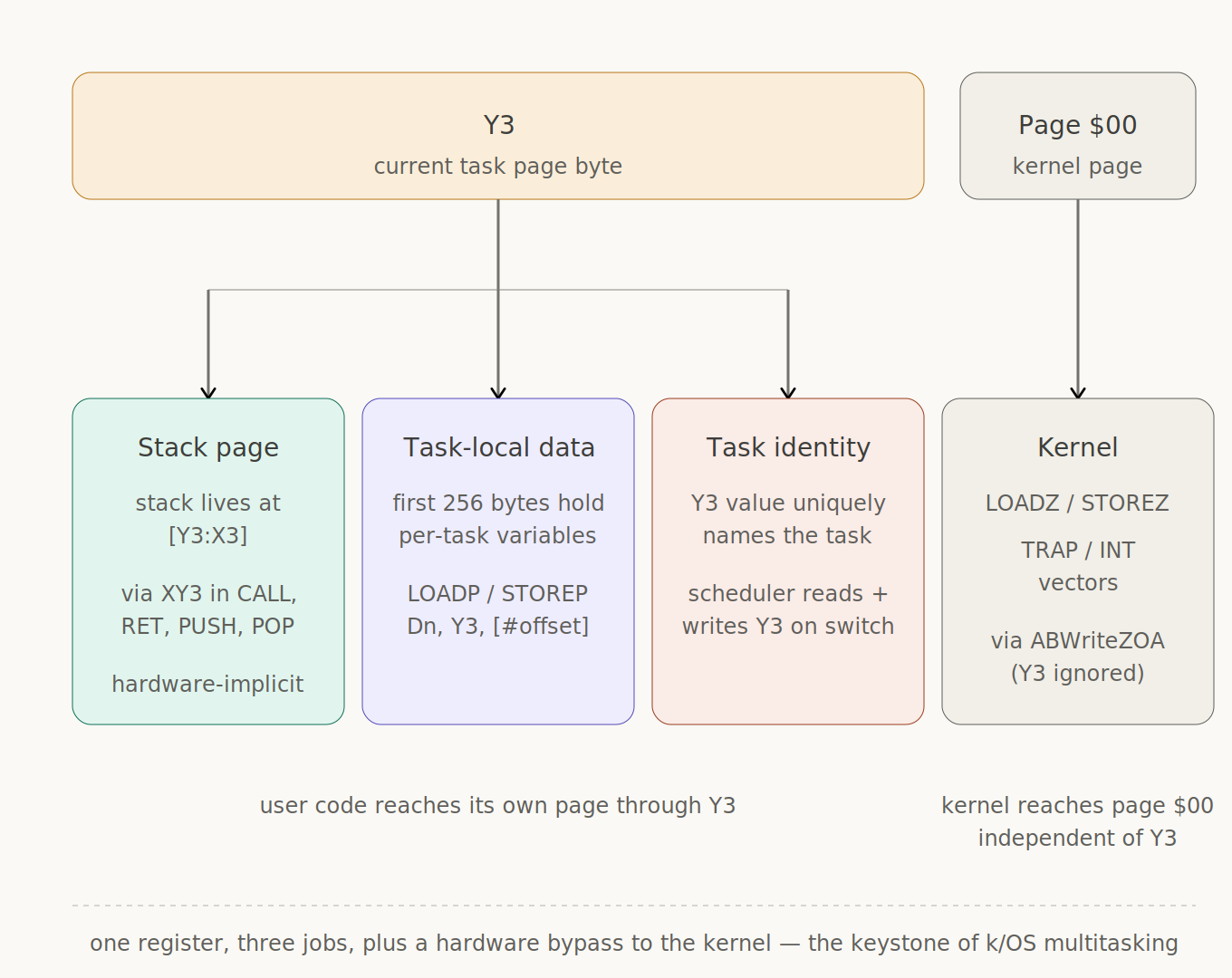
Building k/OS from scratch on the K16 has been a slow burn of “wait, I already have that” moments. The biggest one — the keystone that makes the whole OS work — is Y3.
A bit of background. The K16 has four data registers (D0-D3) and four 24-bit pointer pairs called XY0-XY3, each made of an 8-bit Y (page byte) and a 16-bit X (offset within page). XY3 is wired up as the hardware stack pointer — CALL, RET, PUSH and POP all use XY3 implicitly. So Y3 started life as one thing only: the page byte that says where the stack lives. Set it once at reset, leave it alone, done.
Then I started writing Forth, and ran into the classic problem: not enough registers. Forth’s inner loop wants the IP, the data stack pointer, the return stack pointer, the dictionary pointer, and a handful of system variables all reachable fast. The K16 only has four XY pairs, and burning one on every variable access wasn’t going to fly.
The 6502 solved this with zero page — a special 256-byte region the CPU could reach in one instruction. I wanted the same thing on the K16, but better: I had 24-bit addressing, so I could pick any 64KB page as my “zero page”. The mechanism would be a new instruction family — LOADP, LOADPB, STOREP, STOREPB — that takes a Y register as a page selector and a 16-bit immediate as the offset. LOADP D0, Y3, [#$0108] reads from memory at Y3:$0108.
And then I noticed Y3 was already sitting there, set to $00, doing nothing between resets. So Y3 became the default page register for “zero page” access — for free.
The cycle savings are not subtle. The “proper” indexed way:
LOADI Y0, #$00 ; 3 cycles
LOADI X0, #$0108 ; 3 cycles
LOADD D0, [XY0] ; 3 cycles → 9 cycles, XY0 burned
The Y3 way:
LOADP D0, Y3, [#$0108] ; 3 cycles, no XY register touched
3 cycles vs 9, no XY register consumed. Forth’s register pressure problem went away. I felt clever for about a week.
Then I started designing k/OS and the cleverness fell apart.
The problem: in a multitasking OS, each task needs its own stack. The stack lives at [Y3:X3]. So Y3 has to be per-task — task A has Y3=$01, task B has Y3=$02, etc., each pointing at their own page. Fine.
But the K16’s TRAP and INT instructions dispatch through a vector table at [Y3:0] (for INT) and [Y3:n×4] (for TRAP #n). And the vector table is a kernel thing — there’s one of them, it lives in page $00, every task has to be able to reach it. If Y3 is per-task, vector dispatch breaks the instant you switch tasks.
So Y3 wants to be two things at once: the task’s stack page (per-task), and the kernel’s vector page (fixed at $00). You can’t have both.
The fix: one new chip and a new AB Writer code.
Inside the K16, the address-bus high byte (A16-A23) is driven by a mux that selects from various sources, controlled by a 4-bit “AB Writer” code from the microcode ROM. I added a 74LS541 octal buffer with its inputs tied to GND, gated onto A16-A23 by a new AB Writer code called ABWriteZOA — “Zero on Address-hi, ORAB on Address-lo”. When the microcode asserts ABWriteZOA, the high byte is forced to $00 regardless of any Y register, and the low 16 bits come from ORAB as usual. Full address path to anywhere in page $00.
Then I changed the TRAP and INT microcode at the vector-fetch step to use ABWriteZOA instead of the usual Y-based path.
One new chip. One new microcode writer code. Two microcode cells changed. No new opcode/mode slots used — LOADZ/LOADZB/STOREZ/STOREZB live in the existing $18 and $1D mode 11 slots alongside LOADP/STOREP, distinguished by a single bit (IR4 = ZOA flag) in the instruction word. Same encoding family, no ISA expansion.
After that change, Y3 becomes free to be the current task’s page byte, and everything falls into place. Stack at [Y3:X3] lives in the task’s own page. Per-task variables in the first 256 bytes of that page (task-local zero page, accessed via LOADP/STOREP with Y3). The scheduler switches tasks by loading the new task’s Y3 and X3 from its TCB — and that one register swap simultaneously switches the stack, the task-local data, and the task identity. Vector fetches still work because ABWriteZOA forces them to page $00 regardless of what Y3 says.
The kernel needed a way to explicitly access page $00 (where its own data lives), so LOADP/STOREP got siblings called LOADZ/STOREZ — same idea, but the microcode uses ABWriteZOA instead of the Y-based path. Kernel code uses LOADZ/STOREZ; user code uses LOADP/STOREP and gets its own page. Clean.
Here’s how Y3’s job description grew over the life of the project:
Era Y3’s job Set by Original K16 Stack page register (always $00) Reset vector Forth + zero-page Stack page + default zero-page register ($00) Reset vector k/OS multitasking Per-task page — stack, task-local data, task identity Scheduler on context switch
Three jobs, one register. Which brings me to the thing I like about this most: what I almost added but didn’t.
Early on I sketched out a separate “YS” register — a dedicated stack-page register, distinct from Y3. The pitch was clean: Y3 stays as a per-task data page, YS handles the stack and the vectors, no overloading, each register does one job. I started drafting the microcode changes and the manual section before I bothered to write out what the context switch would actually look like with and without it.
With YS, the context switch needs to save and restore YS from the TCB. Without YS, it needs to save and restore Y3 from the TCB. Same operation, same cycle count, different register name. The “elegance” of separating the two roles cost a whole new architectural register — new opcodes to load it, new microcode entries, new schematic work, new manual sections, new test coverage — to save exactly zero instructions on the hot path.
That kind of thing is easy to miss when you’re staring at a clean diagram. The diagram looks better with two registers doing two jobs. The actual code runs identically either way. Y3 doing three jobs isn’t ugly — it’s the same register holding the same page byte, used for stack access, task-local data, and task identity, because those are all “what page is this task in” questions with the same answer.
The 74LS541 earned its place on the board because it does something Y3 alone can’t — force the address-hi to $00 regardless of what Y3 says, which is what makes vector dispatch survive a context switch. YS would have done nothing Y3 wasn’t already doing. One stayed, one went. That’s roughly the rule across the whole project: hardware has to do work no convention can do for free, or it doesn’t go on the board.
Part 2 — the emulator, the two-target rule, and the magic NOP
In Part 1 I talked about Y3 — the register that holds k/OS together. This post is about the thing that made k/OS possible to debug at all: the K16 emulator, and the discipline of treating it as one half of a two-target system.
A bit of context. The K16 exists in two implementations. There’s the real hardware — discrete TTL modelled in Digital (the gate-level simulator by H. Neemann). And there’s K16EmuIDE, an emulator I wrote in Free Pascal / Lazarus. Same .bin runs on both. Same memory map, same I/O, same microcode behaviour, same everything down to the cycle.
Here’s the thing nobody tells you about gate-level simulation: it’s slow. On my notebook, Digital simulating the K16 at full tilt runs the CPU at about 15 kHz. Fifteen thousand cycles per second. For comparison, the FPC emulator on the same machine in fast mode runs at about 330 MHz. That’s a 22,000× speed gap. Booting k/OS on Digital takes long enough to make coffee. Booting it on the emulator is instant.
The debug tooling gap is, if anything, larger. On the emulator I have step, breakpoint, register inspector, memory inspector, terminal capture, write watchpoints, instruction trace. On Digital I have two things: HALT #$nn (which stops the CPU with an 8-bit code I can read off the bus), and terminal output. That’s it. No step. No inspect. No breakpoint. If something goes wrong on Digital and the terminal doesn’t tell me where, I’m reduced to sprinkling HALT #$01, HALT #$02, HALT #$03 through the code, rebuilding the ROM, and running again to see which one I hit first. Print-statement debugging at fifteen kilohertz.
So why bother with Digital at all? Because Digital is the truth. The emulator is software I wrote. It’s almost certainly wrong somewhere. Digital is a gate-level model of the actual board, and that model is what’ll ship to the FPGA and eventually the discrete TTL build. If something works on the emulator and fails on Digital, the emulator is wrong — or the hardware is. If something works on both, then I trust it.
That’s the two-target rule: same .bin, bit-exact, both targets, or it doesn’t ship. Phase 2 of k/OS — preemptive multitasking, three tasks round-robin under timer IRQ — wasn’t “done” when it worked on the emulator. It was done on 1 May 2026, when the same binary ran identically on Digital and the hex counters on the three task rows updated in lockstep with what I’d seen on the emu the day before.
The rule isn’t just “we test on both”. It’s stronger than that: if the two disagree, that disagreement is the bug. I don’t have to find the bug. The targets find it for me. Then I just need to work out which target was lying.
Which brings me to the four-layer question. When something goes wrong, the bug lives in one of four places:
Emulator — I wrote bad Pascal somewhere
Assembler — wrong bytes emitted from correct source
Microcode — wrong control signals for a given opcode
Hardware — schematic error, or a real-board thing the emu glosses over
Each layer has a different fingerprint. Each has a different fix cost. Emulator bugs are a recompile. Assembler bugs are a recompile but every existing binary becomes suspect. Microcode bugs need a ROM rebuild. Hardware bugs need schematic work and possibly chip changes. Before guessing at the cause I ask which layer it lives in, because that determines what I’m even looking for.
Two war stories show the rule working in opposite directions.
Story one — emulator wrong, Digital right. Forth on the emulator returned ? for every input. 5 → ?. WORDS → ?. Same binary on Digital worked fine. Two targets disagreeing → one of them is wrong → since Digital is the truth and the bytes are identical, the emulator is wrong. I spent a while chasing the wrong thing (cursor handling, terminal noise) before reframing: what does Forth use that BASIC and Pascal don’t? Short list — PUSH Yn, PUSH XY pair, LOADXY, INC XY, LEA. Wrote a tiny test program exercising each. PUSH Yn failed on instruction one. The bug was a single wrong entry in the emulator’s dispatch table — DispatchTable[$06, 3] pointed to ExecPUSH_Imm (push immediate value from instruction word) instead of ExecPUSH_Single (push register Yn). Every PUSH Yn silently pushed the number 6. In Forth’s number parser, that corrupted Y0 to 6, which meant subsequent LOADBs read from page $06 instead of page $00, returning whatever garbage was in uninitialised RAM, which failed digit validation, which produced ?. One-line fix in the dispatch table.
Story two — both targets wrong, both wrong identically. k/OS Phase 2 crashed at exactly the same place on Digital and the emulator. Same PC, same registers, same symptoms. This is the worst kind of failure mode at first glance (”two independent implementations both broken?”) and the best kind once you recognise the pattern: if both targets agree on a wrong answer, the bug is upstream of both of them. Either the assembler emitted wrong bytes, or the microcode does the wrong thing on a perfectly-encoded instruction. In this case it was the assembler — .local labels (.loop, .done) weren’t being scoped per-function. A reference to .done inside _CopyTaskCode resolved to a .done defined ten functions earlier in _RawPuts, producing a branch into completely unrelated code. Both targets faithfully executed exactly the bytes the assembler told them to. One-line fix in the assembler, reassemble unchanged source, Phase 2 worked on both targets the same evening.
Opposite failures, same rule. The two-target discipline isolates the bug to the right layer before I waste hours guessing.
The other half of what makes the emulator carry its weight is a handful of debug-only safety nets — things the emu catches at the exact instruction that did them, where Digital would happily run on and crash twenty cycles later in code that has nothing to do with the actual bug.
The first is break on illegal opcode. The K16’s opcode space isn’t fully populated — there are bit patterns that don’t correspond to any defined instruction. On Digital, executing one of those is undefined behaviour: the microcode ROM returns whatever it returns at that address, and the CPU charges on. On the emulator, hitting an unknown opcode stops the CPU immediately with the offending word and PC in front of me. If I ever execute through a return into the middle of a string literal, or off the end of a function whose RET I forgot, the emu tells me where. On Digital I’d see a crash several screens later and have no idea how I got there.
The second is break on odd-address fetch. Every K16 instruction is word-aligned — the PC’s low bit should always be zero. If a CALL ends up returning to an odd address (corrupted return stack, miscomputed jump target, off-by-one in a JMPT table), the emu catches it the instant the fetch happens. Digital would fetch a misaligned word, decode whatever byte-pair that produced as an opcode, and execute it. Sometimes that’s a NOP and the program limps on; sometimes it’s a CALL into garbage and the whole thing detonates a hundred cycles later in some routine that had nothing to do with the original bug. The emulator turns “ten-minute archeology dig” into “look at this exact instruction”.
The third — and the single most useful debugging trick I’ve built — is the magic NOP.
The K16’s NOP instruction is opcode $00. The bottom 8 bits of the instruction word are loaded into the T8 temporary register and otherwise ignored — NOP #$FF is a perfectly legal instruction that does exactly the same thing as plain NOP. Three cycles, no side effects, T8 gets $FF for nobody to read.
In the emulator I added one check in the fetch loop: if the instruction word is exactly $00FF, drop into step mode at that PC. That’s the entire feature. About six lines of Pascal.
The reason this matters is that the alternative — setting a breakpoint at a specific address — requires me to find the address. Open the listing, scan for the function, read off the PC, type it into the breakpoint dialog. Recompile and the address moves. Add a comment two lines up and the address moves. It’s the kind of friction that adds five seconds to every debug iteration, which adds up to “I’ll just guess what’s happening” before long.
With the magic NOP I write NOP #$FF in the source where I want to break, hit assemble, hit run. The emu stops there. I look at registers, look at memory, hit step or continue, done. If I want a different break point I move the line. No listing math, no address bookkeeping. The break travels with the code through every edit.
(One small caveat: the magic NOP only fires when the emu has live updates turned on — i.e. when it’s actually checking the fetched word against $00FF on every cycle.)
And the killer feature: on Digital, and on real hardware, NOP #$FF is just a NOP. Three cycles, no effect, completely invisible. I can leave magic NOPs scattered through k/OS during development and the production build behaves identically — they cost three cycles each and nothing else. (For a release build I strip them with a sed pass, but honestly even leaving them in costs almost nothing.)
That’s the pattern across all three of these: the emu gets the debug feature, the hardware doesn’t pay for it. Illegal opcode catching, odd-address catching, magic NOP — none of them exist in Digital. They can’t. Digital is gate-level; you can’t graft “stop the CPU and let me poke around” onto a circuit. But the emulator is software, and software can have whatever guard rails it likes, and as long as the defined behaviour matches Digital cycle-for-cycle, the guard rails are free.
Between the speed gap, the debug tooling, the two-target rule, and the three guard rails, k/OS went from “could be done eventually” to “actually getting done”. I genuinely don’t know how I’d have built any of this on Digital alone. The emulator earned its keep on day one and hasn’t stopped.
Part 3 next — the ISA changes that k/OS forced out. PUSH/POP D123, RETCC and RETCS, JMPT and the tight IRQ path, and the flag awareness that bites you the first time you put a conditional branch after INC XYn.
Part 3 — the ISA changes k/OS forced out
In Part 1 I talked about Y3. In Part 2 I talked about the emulator and the two-target rule. This post is about what happened when I started writing actual k/OS code and the ISA pushed back.
A clean ISA on paper is one thing. A clean ISA you can write a preemptive multitasking kernel in is another. Every time I wrote a syscall handler, an IRQ dispatcher, or a context switch, the K16 surfaced something that almost worked but had a sharp edge. Most of the time the fix was small — a microcode tweak, a new mnemonic, a documented gotcha. But “small” doesn’t mean “obvious”, and getting these right took until I’d written enough handlers to feel the pattern.
This post is six of those, roughly in the order I tripped over them.
1. PUSH D solved the wrong problem.
When I designed the K16’s stack opcodes, I added PUSH D and POP D as a convenience — push all four D registers (D0/D1/D2/D3) in one 14-cycle instruction instead of four separate 3-cycle pushes. Same for POP. Obvious design choice: if you’re going to save data registers, you probably want to save all of them, right?
Wrong, as it turned out — but I didn’t find out until I started writing k/OS handlers.
The K16’s calling convention (V2 ABI) uses D0 as the result register. A function returns its result in D0. A syscall returns its result in D0, or an error code in D0 with the carry flag set. So a handler that starts with PUSH D and ends with POP D does this:
sys_something:
PUSH D, XY3 ; save D0/D1/D2/D3
...
LOADI D0, #result ; compute the return value
POP D, XY3 ; restore D0/D1/D2/D3 — clobbers D0!
RET ; returns whatever was in D0 BEFORE the handler ran
POP D undoes the very thing the handler was trying to return. Useless. And not just useless in this handler — useless in every handler that returns a value, which is basically all of them.
I started counting where PUSH D could legitimately be used. It needed to be a function that doesn’t return anything in D0, and doesn’t set the carry flag for error reporting, and genuinely uses all four D registers as scratch. That’s almost nothing. Even the IRQ handler — which seemed like the obvious case (”save everything, restore everything”) — saves the preempted task’s registers individually, because the IRQ frame layout is part of the TCB, not a stack-temp.
So PUSH D existed because I’d assumed at design time that “save all four” was the common case. In real OS code it was the opposite of the common case. What handlers actually want is to save the callee-saved set — D1, D2, D3 — and leave D0 alone so the return value survives.
I replaced PUSH D with PUSH D123 at the same encoding. Same opcode/mode slot ($06/$07 mode 01), same instruction word, just new microcode that pushes only D1/D2/D3 and skips D0 entirely. Three pushes instead of four, 11 cycles instead of 14, and D0 is never touched so the result register survives. Every callee-saved-register prologue in k/OS now looks like:
sys_something:
PUSH D123, XY3 ; save D1/D2/D3 only
PUSH XY2, XY3 ; V2 ABI: XY2 also callee-saved
...
LOADI D0, #result
POP XY2, XY3
POP D123, XY3
RETCC ; (more on this in a minute)
11 cycles for the prologue vs 12 cycles for three individual PUSH D1 / PUSH D2 / PUSH D3 instructions, and one word of code instead of three. Faster, denser, and impossible to use wrong — the assembler rejects PUSH D outright now with an error pointing at PUSH D123. The K16 design choice that bit me here wasn’t a bug — it was a perfectly defensible assumption that turned out to disagree with how OS code actually wants to be written.
2. RETCC and RETCS — return + flag write in one instruction.
The pattern that kept showing up in syscall handlers is “do the work, return success, but if something went wrong return an error code with the carry flag set so the caller can BCS on it.” That looked like this:
; success path
CLC ; carry clear = success
RET
err: LOADI D0, #ERR_BUSY
SEC ; carry set = error
RET
Three instructions on each exit path. Doable but ugly, and the SEC/CLC + RET pair is just begging to be one instruction.
So I added two new opcodes: RETCC (return + clear carry) and RETCS (return + set carry). Both share opcode $1E mode 01, discriminated by IR[5]. Same cycle count as plain RET. The handler pattern becomes:
; success path
RETCC ; one instruction: clear carry, return
err: LOADI D0, #ERR_BUSY
RETCS ; one instruction: set carry, return
Cleaner to write, harder to get wrong, and the caller can do CALL sys_something / BCS err_handler with no compare in between.
This is the kind of change that only earns its keep when you’ve written enough handlers to feel the friction. Looking at one handler, SEC/CLC + RET is fine. Looking at fifty handlers, you want the instruction.
3. JMPT — one instruction that makes the IRQ path tight.
K16’s interrupt entry point is at $00:0000. The K16 has 8 IRQ levels (0-7), and the dispatcher’s job is to read the IRQ level off the saved SR and jump to the handler for that level.
The instruction that makes this work is JMPT — “jump via table”. JMPT XY1, D0 reads a 16-bit address from memory at [XY1 + D0] and jumps to it. Four cycles. The table lookup and the indirect jump are one instruction.
Here’s the actual k/OS IRQ dispatcher:
_INTDispatch:
PUSH D0, XY3
PUSH XY1, XY3 ; save XY1 — about to clobber for JMPT base
LOADD D0, [XY3+#6] ; saved SR (after PUSH D0 + PUSH XY1 = 6 bytes)
AND D0, #$0070 ; mask IRQ level field
SHR D0
SHR D0
SHR D0 ; D0 = level × 2 (word offset)
LOADI Y1, #>_IRQ_VECS
LOADI X1, #<_IRQ_VECS
JMPT XY1, D0 ; jump to _IRQ_VECS[level]
Ten instructions. That’s the entire IRQ dispatch, from entry to handler call. The JMPT line at the bottom does the work three other lines would have done on a CPU without table-jump — load address from memory into a register, jump to register. Here it’s one instruction.
JMPT is also what the TRAP table runs on. Same primitive, different table. TRAP #n fetches a vector from [$00:n×4] (via the ABWriteZOA mechanism from Part 1) and dispatches — same shape, same speed.
If I had to pick one instruction that’s done the most work in k/OS for its weight, it’s JMPT. Every syscall, every IRQ, every state-machine dispatcher in the OS goes through it.
4. Register discipline — and the dispatcher that didn’t follow it.
The V2 ABI says:
D0, D1, D2 — argument registers (caller can clobber)
D0 — return / error register
D2, D3, XY2 — callee-saved (must be preserved across a call)
Everything else — caller-saved
Every function in k/OS has to follow that. Including the things that aren’t quite functions — like the IRQ dispatcher.
The IRQ dispatcher is special: it doesn’t get called, it gets entered by hardware when an interrupt fires. The CPU pushes PCL, PCH, and SR onto the preempted task’s stack, then jumps to $00:0000. Whatever the preempted task was doing — whatever registers it had in flight — needs to be exactly the same when control returns. That’s not “callee-saved” in the ABI sense; it’s “everything-saved”. The dispatcher has to save and restore every register it touches, because every register might be live in the preempted task.
I wrote the first version of _INTDispatch and got it wrong. It looked like this:
_INTDispatch:
PUSH D0, XY3
LOADI Y1, #>_IRQ_VECS ; ← clobbers Y1 before saving it
LOADI X1, #<_IRQ_VECS ; ← clobbers X1 before saving it
; ... compute index ...
JMPT XY1, D0
The bug: I loaded XY1 with the IRQ vector base before saving the preempted task’s XY1. If the preempted task had been using XY1 — as a pointer into a buffer, say — its XY1 was now gone. The handler ran, returned, the preempted task resumed... and a few instructions later its pointer was pointing at the IRQ vector table.
This is the kind of bug that’s invisible until exactly the wrong context switch happens. The fix was one line: PUSH XY1, XY3 immediately after PUSH D0. Save first, clobber second. Obvious in hindsight; not obvious when you’re writing it and thinking about the JMPT.
The rule that came out of it: anything that touches a register has to save it first, even if “I’ll restore it before anyone notices” seems true at the time. Because in a preemptive OS, “anyone” includes a task whose execution you suspended mid-instruction, and what they notice is that their pointer just changed.
5. Flag awareness — the INC XYn trap.
The K16’s rule for flags is simple: only ALU operations and CMP write flags. Everything else leaves SR alone. So you can LOADD D0, [XY1] / CMP D0, #limit / BLT loop and the BLT branches on the CMP result, because LOADD doesn’t touch flags. Clean.
Except for one case I tripped over: INC XYn and DEC XYn do write flags.
Not deliberately — it’s a side effect of how the microcode works. INC XYn is a 24-bit increment: add the immediate to the 16-bit X, then propagate the carry into the 8-bit Y. To propagate the carry, the microcode has to write the carry from the X add somewhere — and that “somewhere” is the SR. As a side effect, Z, N, and V get written too, with values computed from the 16-bit X half of the operation, not the full 24-bit result.
The result is that this code is wrong:
CMP D0, #640
INC XY1, #1b ; advance pointer
BLT .loop ; branches on INC flags, NOT on CMP!
The BLT branches on whatever the INC put in SR, not on the CMP. It looks right; it isn’t.
I went back and forth on whether to fix this. The options were:
Fix it in hardware. Add an internal carry latch so the microcode can propagate carry between steps without writing SR. Cost: about half a flip-flop’s worth of an existing chip plus two new chips to hold the internal carry — call it 2.5 chips of TTL — for a single workaround. Not worth it on the discrete TTL build.
Fix it in microcode without new hardware. Save SR before the X add, restore it after the Y propagation. Adds two cycles to every INC/DEC XYn in the system. Possible, but pricey.
Document it LOUDLY and move on. Branch before the increment, not after. Costs nothing.
I went with the third option.
The rule that came out: state the flag effect of every instruction out loud before typing the next branch. ALU and CMP write flags. INC/DEC XYn writes flags. Everything else doesn’t. Branch on the flags from the last thing that actually wrote them.
6. The 6502 carry trap.
K16 carry semantics are 6502-style, not x86-style. After SUB or CMP:
C=1 means no borrow (result ≥ 0, the normal case)
C=0 means borrow occurred (result < 0)
So BCS after a CMP means “branch if result ≥ 0” — the normal case, not the error case. This is the opposite of x86, where JC (jump if carry) after a CMP means “operand 1 < operand 2”.
If you’ve ever written x86 you have an autopilot. The autopilot is wrong on the K16. I’ve hit this often enough I now have a reflex for it — usually in a comparison whose branch goes the wrong direction and produces an off-by-one that looks like a different bug entirely.
The rule that came out: state the carry sense out loud before typing the branch mnemonic. Not “BCS branches on carry” — “BCS after CMP A,B branches if A ≥ B unsigned”. State what the comparison means, then pick the branch. Skip the intermediate step and the x86 autopilot wins.
(The K16 also has BHS and BLO as aliases for BCS and BCC that read more naturally after a CMP — “branch if higher or same”, “branch if lower”. I use those now. The autopilot trips less often when the mnemonic spells out the comparison.)
That’s the six. Each one cost a handler or three before I felt it. Each one is now either a microcode change, an ISA addition, or a documented rule that travels with the code.
The pattern I keep coming back to: an ISA on paper looks fine until you write the OS on it. Then the rough edges show up, one at a time, in the order you need them. The good news is they’re almost all small — PUSH D123, RETCC/RETCS, the documented INC/DEC gotcha — none of these are large changes. The bad news is none of them are obvious in advance. You have to write the kernel to find out which corners of the ISA matter most.
One thing worth saying about the speed of all this. The bulk of the K16 ISA design and testing — Forth, BASIC, the initial Pascal compiler work, the early k/OS pieces — happened on Digital, before I’d built the emulator. Digital at 15 kHz is painful, and that pain is a teacher. Every instruction you write is a cycle you wait for. You count cycles because you can feel them. If a loop is wasteful, you notice immediately. If the IRQ path is 50 cycles instead of 30, you notice that too. The slow target forced me to design tight from the start.
I’m not sure I’d have made the same choices on the emulator. At 330 MHz nothing feels slow, so nothing pushes back. JMPT might not have happened. The RETCC/RETCS pair might not have happened. The PUSH D123 redesign almost certainly wouldn’t have — PUSH D “works fine” if you’ve got cycles to burn. The emulator turned out to be invaluable for building k/OS, but I think Digital is what made the K16 worth building k/OS on.
And the original design target, from before any of this existed: I wanted a CPU that was actually nice to code in assembly on. Not a toy, not a teaching example, not something you tolerate because it’s homebrew. Something where writing a kernel or a Forth or a Pascal compiler feels good. Six iterations of “this almost works but” later, I think it’s getting there. The ISA on the page today is meaningfully nicer to write than the one I started with — and the things that made it nicer all came from writing real code on it. Which, in retrospect, is the only way it was ever going to happen.
Part 4 next — the assembler picking up the slack with pseudo-opcodes. SHL Dn, #6 expanding to whatever combination of native shifts gets the job done in the fewest cycles. BHI / BLS, which the ISA never quite had but the assembler now does. Hardware doesn’t have to change for the code to read better.
Part 4 — Pseudo Opcodes
When the assembler does the real work
Part 1 was about Y3. Part 2 was about the emulator. Part 3 was about the ISA changes k/OS forced out. This last one is about the changes that aren’t ISA changes at all — pseudo-opcodes. Things the assembler recognises and expands, with no microcode, no ROM burn, no schematic change, and no encoding slot consumed. The hardware doesn’t even know they exist.
The reason they exist is code review.
Whilst developing k/OS I noticed there was a fair bit of this type of code:
SHL4 D0
SHL D0
SHL D0
Three instructions for “shift left by six”. Anyone reading this code has to count the instructions to know the shift count. Anyone writing it has to do the decomposition in their head every time. If I’d wanted left-by-7 I’d have written SHL4 / SHL / SHL / SHL, and at first glance that’s indistinguishable from left-by-6. The code is correct but that’s not nice.
I noted it, kept going. That’s been the pattern across the whole project — build something in K16 assembly, finish it, read the code back, and feed what made it harder than it should have been into the next pass of the ISA or the assembler. After Forth came LOADP/STOREP and the SCC family. After BASIC came JMPT. After Pascal came a batch of assembler directives (.BYTE, .ALIGN, .DS, .INCLUDE) and proper local labels. After the first cut of k/OS came the changes in Part 3.
The pseudo-opcodes are the latest pass. SHL Dn, #n and BHI / BLS are the things that finally got fixed after surfacing in all four codebases. When the same problem turns up four times you stop noting it.
The reason the K16’s shifts work this way is a hardware constraint. A real shifter — one that can shift by an arbitrary count in one instruction, like x86’s SHL EAX, CL — is a chunk of muxes you don’t want to build in discrete TTL. So the K16 doesn’t have one. The K16’s “shifts” are ALU ROM lookups: SHL shifts left by one bit (one entry in the ALU ROM), SHL4 shifts left by four (another entry). Plus the byte-level helpers — LOW zeros the high byte, HIGH zeros the low byte, SWAPB swaps the byte halves, ASR8 sign-shifts down by eight. Each is a ROM lookup. Single-bit, 4-bit, byte-level shortcuts. Anything else is a combination.
That’s what the assembler now does for you. SHL Dn, #n for any constant n from 0 to 16 picks the shortest known sequence of native ops. The source code now looks like:
SHL D0, #6
The assembler emits the same three instructions — SHL4 / SHL / SHL — that I would have hand-rolled. Nine cycles, three words. The binary is identical. The source is one line that tells you what you meant.
Here’s the decomposition table the assembler uses for SHL:
Pseudo Expansion Cycles Words SHL Dn, #01 SHL 3 1 SHL Dn, #04 SHL4 3 1 SHL Dn, #05 SHL4 / SHL 6 2 SHL Dn, #06 SHL4 / SHL / SHL 9 3 SHL Dn, #08 LOW / SWAPB 6 2 SHL Dn, #12 SHL4 / SHL4 / SHL4 9 3 SHL Dn, #15 SHL4 / SHL4 / SHL4 / SHL / SHL / SHL 18 6 SHL Dn, #16 LOADI Dn, #0 2 1
The row that makes me smile is SHL Dn, #08 — it’s not three shifts of four bits and four of one bit, it’s LOW / SWAPB. Zero the low byte, swap the halves, you’ve shifted left by 8 in two instructions. Six cycles. That’s the kind of thing you’d notice once you’d hand-rolled it for the third time, and then forget the next time, and then re-derive it. The assembler does it every time, doesn’t forget, and produces the right output.
SHR Dn, #n and ASR Dn, #n have their own decomposition tables — SHR uses HIGH for unsigned >>8, ASR uses ASR8 for signed >>8. Same principle: source code says what you meant, assembler picks the optimal native sequence.
There’s one wrinkle worth mentioning. K16 shifts are lookup-class instructions, and lookup-class instructions don’t touch flags. That’s deliberate — it means you can write:
CMP D2, #LIMIT
SHL D0, #15
BEQ .equal
and the BEQ correctly branches on the CMP, because the 18-cycle, 6-instruction SHL expansion never wrote SR. Useful guarantee. But it’s expensive — SHL Dn, #15 is the worst case in the table, six instructions to shift left by fifteen.
If you don’t need the flags, there’s a much cheaper sequence using AND and ROR:
AND D0, #1 ; keep only bit 0
ROR D0 ; rotate into bit 15
Two instructions, six cycles. Same final value in D0. But AND and ROR both touch flags, so this is only safe if there’s no live CMP result you care about.
The assembler can’t make that call for you — the wrong choice silently corrupts the program logic. So it does the right thing: it always emits the safe (flag-preserving) version by default, and emits a hint when there’s a faster flag-touching alternative available. The hint is informational only. Your code keeps working, the hint sits in the assembly listing, and if you care about the cycles you switch to writing the AND/ROR explicitly. Pseudo-opcodes default to safe; the optimisation is opt-in.
The same code-review pattern surfaced a second pseudo-opcode area: conditional branches.
K16’s conditional branch hardware uses a 74LS151 — an 8-to-1 mux — to select which flag combination gates the branch. Eight inputs, one output, one branch taken/not-taken decision. That gave me eight native branch conditions to spend, and I spent them on the obvious ones: BEQ/BNE, BCS/BCC (aliased BHS/BLO), BMI/BPL, BVS/BVC, plus the signed-comparison set BLT/BGE/BGT/BLE. Eight inputs, eight conditions, mux full.
What I didn’t have native room for was BHI (strictly higher, unsigned) and BLS (lower or same, unsigned). Adding them would have meant a wider mux and more decode logic — several more chips to get two more conditions. For a long time the workaround in source code was to reverse the operands of the CMP and use the opposite branch:
; want: branch if D0 > LIMIT (unsigned strict)
CMP LIMIT, D0 ; reversed!
BLO .reject ; LIMIT < D0 means D0 > LIMIT
This works. It also makes me stop every time I read it. “Wait, that CMP is the wrong way around — oh, right, because we want BHI but we only have BLO.” It’s the kind of indirection that’s fine for the person writing it in the moment and a small mental tax for everyone reading it later (including the person who wrote it, three months on).
BHI and BLS are now pseudo-opcodes. The source reads what you actually meant:
CMP D0, D1
BLS .skip ; D0 ≤ D1 → skip update
MOVE D1, D0 ; update max
.skip:
What the assembler actually emits for that BLS:
CMP D0, D1
BEQ .skip ; equal? branch to .skip
BLO .skip ; lower? branch to .skip
MOVE D1, D0
.skip:
Two instructions where the hand-rolled reversed-CMP version was one. Both branches target the same user label — no extra label needed. BHI works the same way but inverted: BEQ.S over a BHS, with a synthetic skip label to make “strictly greater” out of “greater or equal”. Same trick, two instructions per pseudo, identical binary to the hand-rolled version.
The 74LS151 didn’t have room for these two conditions; the assembler does, two instructions where a native branch would have been one. Worth the extra word.
The pattern across all of this: the hardware doesn’t need to change for the code to read better. Pseudo-opcodes cost nothing on the silicon side — no microcode, no ROM, no encoding slot, no schematic. They live entirely in the assembler. The trade-off is that the assembler has to know the decomposition tables, and the user has to understand that the source mnemonic may expand to multiple native instructions. Both of those are fine — the assembler is software, it can be as smart as it needs to be, and the listing makes the expansion completely visible.
Where pseudo-opcodes are not the answer: anything that needs atomicity (a context switch primitive — the user has to control exactly which instructions run in exactly which order), anything the user genuinely needs explicit control over (which is why SHL’s faster-but-flag-touching alternative stays opt-in), and anything where the “expansion” is conceptually a different operation rather than a synonym. Pseudo-opcodes work because they’re synonyms for native sequences. The moment they’d hide a semantic difference, they stop being a good idea.
That’s the four. Y3 doing three jobs and surviving every context switch. The emulator and the two-target rule, with the magic NOP and the guard rails the hardware can’t have. Six small ISA changes that fell out of writing real OS code. And a handful of pseudo-opcodes that the assembler picks up so the source reads what you meant.
The pattern I keep coming back to: the K16 didn’t get better from big design moves. It got better from a lot of small ones, each driven by writing real code on it. None of these changes are flashy. None of them would have shown up if I’d written a paper design and shipped it. They showed up because I built a Forth and a BASIC and a Pascal compiler and started writing a kernel, and each of those pushed back on the architecture in different places.
Y3 wasn’t there at the start; PUSH D123 wasn’t there at the start; the magic NOP wasn’t there at the start; the pseudo-opcodes weren’t there at the start. They came from the work. I think that’s how this stuff is supposed to go.
What’s next on the kernel side: file system on the SD card, proper userland with a shell that does pipes, maybe a windowing layer if I can keep the framebuffer code under control. But the architecture and ISA work is mostly done — the K16 today is a CPU I genuinely enjoy writing assembly on, which was the goal from the start. The OS gets to be the focus from here.
Thanks for reading. Comments and questions welcome